统计学精品课程:第三章 数据的描述




当我们面对一大堆数据时,往往使人眼花缭乱。没有人能够记住那些巨大的数据中的所有数值,但总是可以对数据形成一些印象。有些特征大略了解一下就可以得到:
这些数据的大致范围;是定性还是定量;有多少变量;收集该数据的目的等等。
本章介绍如何来简单用图表和少数的一些数字来概括数据的某些特征。
当然,由于数据是从总体中产生的,其特征也反映了总体的特征。对数据的描述也是对其总体的一个近似的描述。
第一节 用图来表示数据
一、如何用图表来显示数据?
变量分为定性变量和定量变量:
定性变量主要反映现象的分类情况,
定量变量主要反映现象的数值大小;
因此对不同的变量采用的图形表示也不相同
二、定量变量的图表示
表示定量变量常用的图形:
直方图、盒型图、茎叶图、散点图
直方图
对于一个定量变量,比如某个地区(地区 1 )学校高三男生的身高;有 163 个度量。
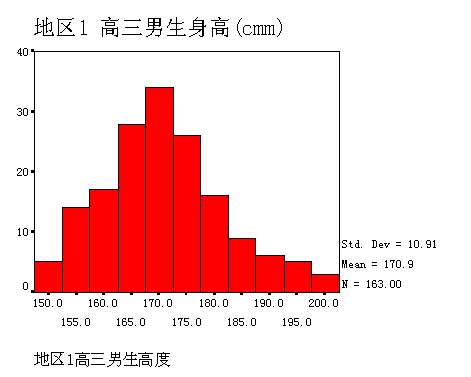
如何用图形来表示这个数据,使人们能够看出这个数据的大体分布或 “ 形状 ” 呢?一个办法就是画一个直方图 (histogram) 。 Spss 选项 :Graphs-Histogram (图 3.1 )
该图的横坐标是身高区间,这里每一格代表 5cm 的身高范围(格子宽度因不同的数据或要求而定),而纵坐标为各种身高区间的身高的频数。 比如在 170cm 左右 5cm 范围的观测值有 34 个(最高的一个矩形条),而 165cm 附近 5cm 内有 28 个(第二高的矩形),在 175cm 附近 5cm 范围有 26 个,而在 2 米 附近的区间只有 4 个观测等等。 直方图的纵坐标也可以是百分比,即把频数除以样本量。显然用百分比得到的图形和用频数所得到的形状一样;只是量纲不同而已。
盒型图
比直方图简单一些的是盒形图 (boxplot ,又称箱图、箱线图、盒子图 ) 。图 3.2 的左边一个是根据地区 1 高三男生的身高数据所绘的盒形图;其右边的图代表另一个地区(地区 2 )的高三学生的身高。

盒子的中间横线是数据的中位数 (median) ,它是下节要引进的量之一。顾名思义,中位数是数据中占据中间位子的数,即数据中有一半大于中位数(在其之上),另一半小于中位数(在其之下)。 Spss 选项 :Graphs-Boxplot (图 3.2 )
封闭盒子的上下两横线(边)为上下四分位数(点);其意义为:数据中有四分之一的数目大于上四分位数,即在盒子之上;另外有四分之一的数目小于下四分位数,即在盒子之下。 因此有一半的数目在中间封闭盒子的范围内。有一半分布在盒子上下两边。
在盒子上下两边分别各有一条纵向的线段,表明盒子外面点的分布。 若干个盒形图往往放在一个图中比较。从图中可以看出左面的度量比右边的分散得多,但总的来说似乎地区 1 的学生要高一些。 按照 SPSS 的默认选项,如果所有样本中的数目都在离四分位点 1.5 倍盒子长度之内,则线的端点为最大和最小值。 距离四分位数大于 1.5 倍盒子长度的数值点则被软件认为是离群点 (outlier) ,单独点出; 而超过盒长三倍的被认为是极端值 (extreme) 。当然不同的软件及不同选项所生成的盒形图两头线长的定义不尽相同,但封闭盒子长度的定义基本一样。
茎叶图
在上面介绍的直方图和盒形图中,已经看不到数值,因此很难恢复数据的原貌。 下面引进另一种图:茎叶图 (stem-and-leaf plots) 。 以地区 1 高三男生身高为例的,茎叶图既展示了分布形状又有原始数据。它像一片带有茎的叶子。茎为较大的数目,图 3.3 是用 SPSS 画的地区 1 高三男生身高的茎叶图 (SPSS 数据文件: S3height1.sav) ,虽然看起来不象一个 “ 图 ” 。
地区 1 高三男生高度 Stem-and-Leaf Plot
Frequency Stem & Leaf
9.00 15 . 001223344
17.00 15 . 55666667778899999
20.00 16 . 01112222223333333444
35.00 16 . 55555666666667777788888888888999999
25.00 17 . 0000000011112222233333344
24.00 17 . 555666677777777777888899
13.00 18 . 0111111122333
11.00 18 . 55667788899
4.00 19 . 2333
2.00 19 . 56
3.00 Extremes (>=198)
Stem width: 10.00
Each leaf: 1 case(s)
SPSS 选项 :Analyze-Descriptive Statistics-Explore (图 3.3 ) 其中茎叶图中茎的单位为 10cm ,而叶子为个位。 比如第一行茎为 150cm ,叶子为 150 、 150 、 151 、 152 、 152 、 153 、 153 、 154 、 154cm 等。每行左边有一个频数(比如第一行有 9 个数目,第二行有 17 个等等);可以看出最长的一行为从 165cm 到 169cm 的一段(有 35 个数)。
散点图
人们得到的数据也可能有两个变量,比如美国男士 和 女士初婚年限的数据( SPSS 数据: marriage.sav )。 该数据描述了自 1900 年到 1998 年男女第一次结婚延续的时间。这里年份是一个变量,而结婚延续时间是第二个变量。

由于不可能将所有人的婚姻年限都给出来,所以每年就取了一个中间的值 ( 中位数 ) 作为代表。自 1900 到 1960 年是每十年一个值,以后到 1990 是每五年取一个数, 1995 年以后是每年一个数。 SPSS 选项 :Graphs-Scatter( 图 3.4)
由于分男士和女士,因此有两个二维数据。这时可以用一个变量为横坐标(如年份),另一个为纵坐标(这里是结婚年限)来点图(图 3.4 )。这种图称为散点图( scatter plot )。 还可以看出在二十世纪六十年代婚姻年限降低,而后来又升高。而男子的年限平均比女性长。这个图是用 SPSS 画的。 为什么男女初婚年限不一样 ? 这是因为初婚一方的配偶不一定也是初婚。
三、定性变量的图表示:
定性变量(或属性变量,分类变量)不能点出直方图、散点图或茎叶图,但可以描绘出它们各类的比例,常用饼图和条形图表示。
饼图
下面用 SPSS 绘的图 3.5 表示了说世界各种主要语言人数的比例 (SPSS 数据: language.sav) 。 该图看不出具体说各种语言的具体人数,但可以看出比例,而且如果知道世界总人口,也可以大致推算出说各种语言的人数。

这种图叫做饼图( pie chart )。如果有太多的类别,那么饼图就不那么好看了。
SPSS 选项 :Graphs-Pie( 图 3.5)
条形图
而用同样数据( language.sav )画的图 3.6 (用 SPSS 绘制)称为条形图( bar chart )。 从每一条可以看出讲各种语言的实际人数,而且分别给出了每个语种中母语和日常使用的人数(在图中并排放置)。
SPSS 选项 :Graphs-Bar

第二节 用少量数字来概括数据的特征
用一两个数字概括大量数字是日常生活中常见的。比如说,北京人的平均收入是多少;东西部的收入差距是多少,高收入的人占人口的百分比等。这些 “ 平均 ” , “ 差距 ” 或百分比都是用来概括的数字。
一、定性变量的数据描述
由于定性变量主要是计数,比较简单,常用的概括就是比例、百分比、中位数和众数。
中位数 (median)
中位数是数据按照大小排列之后位于中间的那个数(如果样本量为奇数),或者中间两个数目的平均(如果样本量为偶数)。
众数
众数就是数据中出现次数或出现频率最多的数值。
在定性变量中,由于记录的是频率,因此众数用得多些。比如在图 3.6 的关于语言的饼图中,可以看出众数就是由 “ 其他 ” 语种代表;这是因为无论是母语还是日常使用语, “ 其他 ” 类的频率都最大。当然, “ 其他 ” 不是一个语种。就单一语种来说,还是中国北方话为众数。
用 spss 进行定性变量的数据描述,主要选项:
Spss Analyse Descriptive Statistics Frequencies
二、定量变量的数据描述
统计量和总体参数
除了图表之外,可以用少量汇总统计量或概括统计量 (summary statistic) 来描述定量变量的数据。
通常有:均值 ( 平均数 ) 、中位数、总数;标准差、方差、标准误。
如果这些数字是从样本数据得来的,称为统计量 (statistic) 。
如果这些数字是从总体数据得来的,称为总体参数 (statistic) 。
由于样本本身是随机的,从同一个总体抽出来的不同样本也不一样。因此,对于不同数据或样本,统计量的取值也不一样;所以统计量是随机的。
一些统计量前面有时加上 “ 样本 ” 二字,以区别于总体的同名参数。
比如后面的从样本产生的均值和标准差严格说来应该叫做 “ 样本均值 ” 和 “ 样本标准差 ” ,以区别于总体的均值和标准差;但在不会混淆时可以只说 “ 均值 ” 和 “ 标准差 ” 。一些总体参数将在下一章介绍。
数据的 “ 位置 ”
人们常说哪个地方穷,哪个地方富。也常说,哪个国家人高,哪个国家人矮。
说这些话的人绝对不是说富地方的所有人都比穷地方的所有人富,也不是说,一个国家的人都比另一个国家的所有人都高。他们仅仅省略了 “ 平均起来 ” , “ 大部分 ” 等词语。
这些说法实际上是关于数据中某变量观测值的 “ 中心位置 ” 或者数据分布的中心( center 或 center tendency )的某种表述。和这种 “ 位置 ” 有关的统计量就称为位置统计量 (location statistic) 。
位置统计量当然不一定都是描述 “ 中心 ” 了,比如后面要讲的 k 百分位数。
最常用的位置统计量就是小学时所学到的算数平均值,它在统计中叫做均值 (mean) ;
严格地说叫做样本均值 (sample mean) ,以区别于下一章要介绍的总体均值。
样本均值是把一个变量的所有观测值相加再除以观测值的数目。
以前面的地区 1 高三男生的身高数据为例,身高的均值(平均身高)是 170.9 ;这在前面的直方图所附带的数目中可以看出。它比地区 2 的高三男生的身高均值(均值为 164cm )要高。利用统计软件可以很方便地得出均值。
中位数在数据大小顺序中居中。
而前面提到的上下四分位数(或分别称为第一四分位数和第三四分位数, first quantile, third quantile )则分别位于(按大小排列的)数据的上下四分之一的地方。
一般地还称上四分位数为 75 百分位数( 75 pecentile ,有 75 %的观测值小于它),下四分位数为 25 百分位数(有 25 %的观测值小于它)。
有了 25 百分位数和 75 百分位数的概念,人们就不难理解什么是任意的 k- 百分位数( k-pecentile )了(有 k %的观测值小于它)。
如果令 a=k% ,则 k- 百分位数也称为 a 分位数 (a-quantile) 。显然中位数是 50 百分位数或 0.5 分位数。
众数,除了中位数和均值之外,还有样本中出现最多的数目,称为众数 (mode) ,
高三男生身高数据中 177cm 和 168cm 都是 11 个,因此有 168 和 177 两个众数。
众数反映的信息也不多,又不一定唯一,
在连续变量的情况,可能没有重复的数据,这时也不可能有众数。众数用得不如均值和中位数普遍。
数据的 “ 尺度 ”
有一句老话 “ 不患贫,患不均 ” 。这是指穷一些不怕,怕的是不公平造成贫富差距太大。
贫富是由位置统计量来描述的,而是否 “ 均 ” 是由尺度统计量( scale statistic )来描述的。
尺度统计量是描述数据散布,即描述集中与分散程度或变化( spread 或 variability )的度量。
从两个高三男生身高数据的盒形图(图 3.2 )可以看出,左边的数据平均要高些,但右边的数据散布范围要小得多(数值之间要接近一些)。
统计中有许多尺度统计量。一般来说,数据越分散,尺度统计量的值越大。
常用的尺度统计量有:极差、四分位数极差、标准差、方差。
最简单的就是极差 (range) ;顾名思义,极差就是极大值和极小值之间的差。
盒形图盒子的长度为两个四分位数之差,称为四分位数极差或四分位间距 (interquantile range) ;它描述了中间半数观测值的散布情况。
另一个常用的尺度统计量为(样本)标准差 (standard deviation) 。它度量样本中各个数值到均值的距离的一种平均。
标准差
标准差:它是各个离差的平方和的平均数的开平方。
标准差实际上是方差 (variance) 的平方根。
高三男生身高的两个数据的标准差分别是 10.9 和 5.7 。 ( 方差则是它们的平方: 119.1 和 32.5) 。方差由于和数据的量纲不同,因而在实际应用中使用得不如标准差那么普遍。
标准误差
即使出于同一个总体,样本量相同的不同样本有不同的均值;这种变化的样本均值也是随机变量,它也有均值;所有样本均值的标准差,称为标准误差 (standard error) 。由于不同样本所产生的均值比一个样本中的观测值要稳定得多,它的标准差比针对整个数据的标准差要小得多。
标准误差定义为标准差除以样本量的平方根。
比如地区 1 高三男生数据的标准差为 10.9 ,而除以样本量 163 的平方根 12.77 之后成为大约 0.85 ,即 10.9/ √ (163)=10.9/12.77 ≈ 0.85 。
第三节 数据的标准得分
假定两个水平类似的班级(一班和二班)上同一门课,但是由于两个 任课 老师的评分标准不同,使得两个班成绩的均值和标准差都不一样 (SPSS 数据: grade.sav) 。
分数的均值 标准差
一班 78.53 9.43
二班 70.19 7.00
那么得到 90 分的一班的张颖是不是比得到 82 分的二班的刘疏成绩更好呢?怎么比较才能合理呢?显然,这种均值和标准差不同的数据不能够直接比较,但是可以把它们进行标准化,然后再比较标准化后的数据。
一个标准化的方法是把原始观测值(亦称得分, score )和均值之差除以标准差;得到的度量称为标准得分 (standard score ,又称为 z-score) 。
即: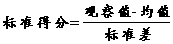
然后可以比较来自不同样本的标准得分。
这样:
张颖的标准得分为: 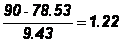
刘疏的标准得分为: 
显然如果两个班级水平差不多,刘疏的成绩应该优于张颖的成绩;这是在标准化之前的数据中不易看到的。
下图展示了这两个班级的原始成绩的盒形图(左边)和标准化之后成绩的标准得分的盒形图(右边)。
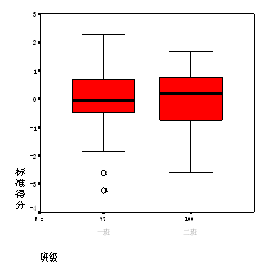
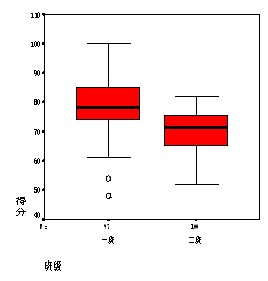
可以看出,原始数据是在各自的均值附近,而散布也不一样。但它们的标准得分则在 0 周围散布,而且散布也差不多。
实际上,任何样本经过这样的标准化后,就都变换成均值为 0 、方差为 1 的样本。标准化后不同样本观测值的比较只有相对意义,没有绝对意义。
标准化之后的数据虽然总的尺度和位置都变了,但是数据内部点的相对位置没有变化。比如,距离均值两倍标准差的一个点在标准化后距离均值还是两倍标准差。
这从图中也可以看出:每个数据标准化前和标准化后的盒形图(在纵向)相似。
这是因为标准化仅仅是把盒形图进行纵向放大(或缩小)和位移。班级 1 的两个离群点还是离群点。虽然如此,但两个不同的数据在标准化后就有了进行比较的基础。
标准得分的思想不仅仅用于比较,而且在后面的推断中也有其用处。另外,计算标准得分也仅仅是许多标准化方法中最常见的一种。
思考题:
1、根据经验,给出定性和定量变量的例子。
2、对于问题 1 的资料,画出各种描述性图形并计算汇总统计量。
3、举例说明众数、中位数和均值的优缺点。
4、尺度统计量说明了数据的什么特性?举例说明。
5、标准得分实际上是对原始数据的一种标准化。试举例说明标准得分的用处。
[来源于:首都经济贸易大学网站]
扫一扫
在手机打开当前页
 关闭
关闭 湘公网安备 43010202000995号
湘公网安备 43010202000995号

