北京市统计数据质量监控系统的设计及其应用




统计数据的准确性是统计工作的生命,没有准确的统计,就不会有正确的决策。小平同志曾指出:“实事求是是马克思主义的精髓,我们改革开放的成功,不是靠本本,而是靠实践,靠实事求是。”错误的统计信息是不能给领导工作带来任何有益的帮助和支持的,甚至会带来误导后果。
当前一些关系经济发展全局的统计数据、涉及利害关系的统计数据、衡量工作成果的统计数据,由于受到来自各方面的干扰,出现程度不同的脱离实际的偏差,给各级党政领导监控形势、制定决策带来极大的困难。因此加强数据质量的研究已迫在眉睫,是当前工作的头等大事。
一、虚假统计数据的危害性
统计数据的质量问题已成为当今社会各界议论统计工作的中心话题,人们纷纷指出,当今统计数据上的弄虚作假行为,已不是一般的思想作风或单纯的统计业务技术问题,其实质是一种十分严重的腐败行为,它的存在和发展,在思想上严重违背了党的实事求是的思想路线,破坏了党的优良传统和作风;在政治上损坏了我们党和政府的形象,助长了地方保护主义和极端利己主义,侵害了国家和人民群众的整体利益,在经济上严重影响国家重要决策的科学性和宏观调控的有效性,影响经济的改革和经济建设的顺利进行。
二、虚假统计数据的来源
(一)利益驱动是诱发统计数字弄虚作假的根源。在社会主义市场经济条件下,尤其是在传统计划经济体制尚未彻底解除,政府职能和企业经营机制尚未彻底转变的转轨时期,同样存在数据失真的气候和土壤。
(二)缺乏科学的评判统计数据真伪的手段。各专业各部门的统计汇总数据,经常性地以经验来判断其真伪,一旦出现问题,往往造成措手不及而束手无策。现代数理统计学方法的引入已迫在眉睫。
(三)统计部门自身的统计制度方法改革置后,统计难度日益增大,也是造成数字不实的原因。改革开放以来,各种经济成份的生产经营单位数量增多,经营方式和分配方式复杂起来,增加了统计调查的难度。
(四)统计标准不完善,执行不严格,资料来源渠道多样。
(五)统计人员素质不高,职业道德观念不强。
三、提高数据质量的措施
鉴于虚假统计数据的危害性,及上述人为因素所造成的虚假统计数据,各级领导应充分认识统计的地位和作用,把弄虚作假虚报浮夸提高到党性的廉政建设、提高到党的事业兴衰成败的高度来认识,把弄虚作假、虚报浮夸作为纪检监察工作的重要内容。因此可责成国家最高权利机关(包括纪检、监察、人事部门)制定有关“反对在统计数据上弄虚作假”的有关规定,此文件一旦出台,将对维护统计数据的准确性发挥重要作用。另外应加大统计法的力度,对基层统计报表的浮夸、虚报以及不负责任的乱填乱报现象给予严肃处理,严重者应诉诸法律部门。
笔者认为,依靠加大政府部门的干预力度(当然不是各级政府过去意义上的对速度下指标、定产量)以及法律、法规的约束,固然是对提高数据质量的行之有效和最主要的办法。而借鉴于数理统计学的有关方法建立起一套评判统计数据的控制系统,在对统计数字真伪的判断上,提供一套科学的、直观的和可操作性的方法。两方面的结合将无异于使在对统计数据质量的研究显得更加有法可依和有章可循。此文将着重探讨如何建立统计数据质量监控系统,以及在各个行业及各专业中应用此系统来评价统计数据的具体方法。
四、建立统计数据质量监控系统的整体思路
统计数据质量监控系统是指以统计数据产生过程、统计数据产生过程中各环节内各影响因素和数据本身为对象,并通过时间序列的理论分析方法,对它们进行控制,以保证统计数据达到规定要求的系统。
建立统计数据质量监控系统通俗地讲就是试图建立一个统计数据的“诊断中心”,每个进入“诊断中心”的指标数据都将接受各种有效的检测。
在构建这个“诊断中心”时,应该拥有一些行之有效的手段和方法,以及相应的软件及硬件环境。包括统计应用软件的支持、具有一定区间长度的数据基础以及寻找经济规律的技术措施。
在做“诊断”之前,需对过去的6个月(年度资料为过去的3年)的经济走势做一个综合评价,以把握当前经济的运行轨迹。然后利用一些近代统计学中关于时间序列分析的方法,对我市改革开放近20年的经济指标进行系统的研究,并结合统计分析的软件进行了大量的试算,探索出了几种对数据质量评价的方法,敬请各位指正。
1.控制系统内的软件和硬件环境
(1)统计应用软件的支持
对大量的统计数据进行处理和分析,离不开统计应用软件。目前,在统计方面已形成上百种的应用软件包。构建这套系统,我们使用了三个分析软件,它们都是当今统计界公认的比较流行和经常被使用的软件包。即: ① SAS(STATISTICAL ANALYSIS SYSTEM)统计分析系统软件包,它具有非常强大的数据处理功能,它的主要功能包括:回归分析、方差分析、多元分析、判别分析、聚类分析等。② SPSS(STATISTICAL PACKAGE FOR THE SOCIAL SCIENCES)社会科学统计软件包,国际上公认的统计分析软件,目前已有汉化的版本。③ EVIEWS(ECONOMETRIC VIEWS,IBM公司设计)时间序列分析软件包,也称做TSP,它在建立模型方面,具有其独到之处。
(2)具有一定区间长度的数据支持
系统中存储有至少是自1978年以来(月度指标多数是1985年以来的)的主要的经济指标,它们都是连续的时间序列。
2.对宏观统计数据进行初始化过程
我们知道,无论是年度还是月度的时间序列,都不同程度地受到季节因素、长期趋势、政策因素以及不规则因素的影响,因此首要的工作是对指标进行初始化。具体步骤如下:
(1)指标的搜集整理
我们对年度和月度数据库中所选的200余项指标进行整理维护月度指标一般从1985年开始;年度指标从1978年开始。
(2)确定一套监控指标,以保证评估的实际操作,入选的指标应具备如下条件:
①指标必须具有经济领域上的重要性,而且必须代表经济活动的主要方面;
②指标必须具有较为重要的政治意义,受到经济管理部门的关注;
③指标必须具有一定的时效性和代表性;
④统计数据的可搜集性和连续性。
根据以上原则,我们从200余个宏观指标筛选出36个指标。
(3)指标的修匀
主要方法有:
X11季节调整法: X11法是美国国势调查局于1965年10月发布的一种精细的季节调整法。随后,日本的官方机构、欧美各国以及一些国际机构都使用它。
BAYSEA调整法:它是日本赤池弘教授于80年代初提出的,它是基于移动平均法的季节调整法。
ARIMA调整法:它是把X11法与时间序列的ARIMA模型结合起来,以克服移动平均法的缺点,并解决时间序列两端欠值项的补值问题。
3.指标的识别过程
所谓指标的识别,即是对每个监控指标的周期特征的描述和定位,同时确立其与总体经济走势的时差关系。这一步骤的主要目的是通过经济指标的周期关系和内在的关联性,来确定监控期统计数据的合理性,其步骤如下:
(1)确定基准循环: 确定基准循环过程是指根据宏观经济扩张和收缩阶段的变动,准确地确定各阶段特别是峰和谷的转折点日期,这种日期一旦确定,实际上就确定了确立时差关系的基准。
(2)划定指标的先行、同步、滞后性
①基本概念:先行、同步、滞后性是相对于基准循环而定的,比如先行指标是指:峰值比基准循环领先3个月(月度指标),先行关系比较稳定,不规则现象较少;指标的经济性质与基准循环有着肯定的、比较明确的先行关系。确定同步与滞后指标与上述标准类似。
②划分方法:运用K-L信息量法、聚类分析法、循环方式匹配法判别两个概率分布的接近程度,以确定指标的先行、同步、滞后性。
③划分结果:
基准循环指标(1个):国内生产总值
先行指标(12个,平均循环长度27个月,平均先行2.7个月):
原煤产量、商业购进、固定资产投资、国有投资、基础设施投资、海关进口、实际利用外资、财政支出、银行贷款、银行现金支出、居民消费支出、消费价格指数。
同步指标(15个,平均循环长度24.5个月):
三产比重、工业增加值、发电量、钢产量、利税总额、轻工业增加值、蔬菜产量、商业销售、旅游人数、财政收入、银行现金收入、常住人口数、平均工资、可支配收入、商品零售价格指数。
滞后指标(8个,平均循环长度24.5个月,平均滞后3.1个月):
产品销售收入、国有工业增加值、综合效益指数、消费品零售额、商业库存、海关出口、批准三资企业数、银行存款。
4.数据诊断的主要方法和测试过程
我们在过去的几个月里,对北京市改革开放20多年的宏观经济数据进行了系统的研究,并结合统计分析的软件进行了大量的试算,探索出了几种对数据质量评价的方法,敬请各位指正。
(1)各专业经济总量的概率落点判断
此方法的基本思路是运用时间序列分析方法,以经济指标的现有数据为基础,利用各个经济变量即经济指标自身发展情况的走势进行最优化模拟,建立相应的模型,通过模型对短期(月度为3个月,年度为2-3年)内的落点进行概率判断,并对相应指标进行预测,即得到该指标在理论上应该达到的数值,然后将此数值与业务部门汇总的数据对比,以此评价汇总的统计数据与理论值的接近程度。
实例说明:我们以工业增加值(规模以上口径,月度时间序列)为例,介绍此方法的具体操作步骤。
数据搜集:指标时间区间为1996年1月至1999年7月
数据的季节调整并建立最优化模型:模型算式为:
GY=17.74+1.02GY(-12)+0.08GY(-24)+[AR(1)=0.90]
AR(1)为一阶自回归项。所谓最优化模型是指在建立模型的过程中,通过修正各项技术参
数,以达最佳时的模型称为最优化模型。
运用模型,推算出1999年1-8月工业增加值的理论落点区间为[375,378],即趋势上应该达到375-378亿元之间,然后与实际统计数据379亿元对比,其偏离度为+0.3%。
数据质量级数的计算: 本系统规定当汇总数落入理论区间内时,则该指标为数据质量一级指标;落入理论区间外0-2.5%之间,为二级指标;落入理论区间外2.5-5%之间,为三级指标;落入理论区间外5%以外,为四级指标。数据质量一、二级指标属于理论上可接受指标,即从历史规律上看,无趋势性冲突;当数据质量达到三级时,应责成有关业务处室给予书面的解释材料;一旦达到四级,就必须请业务部门对基层报表数据重新核查。根据以上原则,本期工业增加值为二级指标数据,属于数据质量可接受指标。
(2)总量指标与各分量指标的区间判断
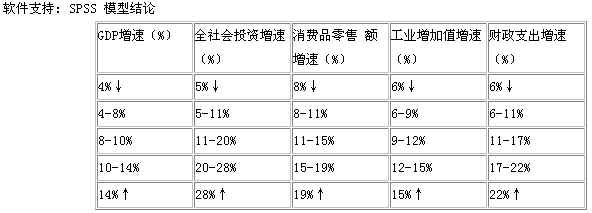
无论是国民经济各行业间还是各个专业内部的各指标数据间都存在着密切的相关关系,某个经济成分的扩张与收缩往往直接影响着其他指标的变化。所以研究指标的依存关系,可以为检测统计数据的质量提供一组量化的、可操作性的依据。主要方法是将总量指标的增长速度划定出5个增速区间段,然后推算出各分量指标相应区间,以此判定未来时期各经济指标速度的接近程度。数据基础:1978-1997年间20年的统计数据。我们就GDP与国民经济主要经济指标的区间关系来论述此方法的设计思想。
该方法的基本思路是根据GDP的历史资料,将其增长速度划定出5个增长速度区间段,然后推算出各指标理论上的相应区间,以此判定未来时期各经济指标速度的接近程度;数据质量监控方法为区间估计法;模型类型采用多元回归模型并结合自回归因素。
(3)各分量指标对总量指标的支撑度判断
运用多元分析方法,选取与总量指标密切相关的分量指标进行多元回归分析并建立相应模型,并测算出以分量指标的数据所能支撑的总量数值。
我们以各专业指标对GDP的支撑为例,总量指标为GDP,分量指标选取固定资产投资(TZ)、工业增加值(GY)、银行贷款(DK)、消费价格指数(WJ)、商业零售额(SY),与GDP进行回归,得到的回归方程为:GDP=1.23+0.14GY+0.12TZ+0.18DK+0.08WJ+[AR(1)=0.17,MA(1)=2.15], 然后分别把各分量指标的数值带入多元回归方程,观察各主要行业的速度能支撑多大的GDP的增长,从而计算出支撑值为10.85%,今年1-8月GDP增速核算值11.04%,,两者有0.19个百分点的差距。
(4)各专业之间数据的匹配关系判断
国民经济各指标间,存在着多种比例关系,能否准确把握住主要经济指标的合理数量界限,界定主要经济指标的趋势范围,是检验其 数据质量的关键。也是我们在此所探索的方法。我们一旦能正确地发现影响宏观调控的主要经济指标间的比例关系,将很容易地检测出未来短期内的数据置信程度。
根据历史资料,利用时间序列分析的有关方法,我们分别测算出各主要指标分别在经济的扩张期、稳定期和收缩期的范围内数量关系,以判断被评价时刻宏观指标的合理性。在此我们研究了如下几组国民经济主要比例关系。
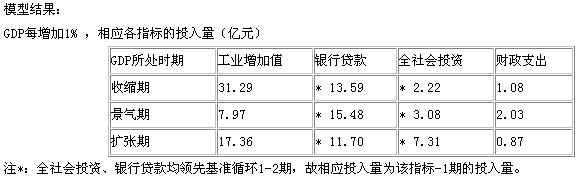
① GDP增长与国民经济各指标间的增长关系

根据历史资料,测算出GDP每增加(减少)1%相应的各经济指标投入量(减少量),分别在经济波动的各个时期即:扩张期、景气期、收缩期分别进行测算。因为经济周期波动是超越体制和发展阶段的普遍现象,它是不以人的意志为转移的。我市自1954年起到1998年,国民经济波动出现了10次(以波谷为分界标志,见上图)平均周期为4.4年。每次周期的振幅不同,在每一周期内,经济发展的特征及各种经济成分的走势都不尽相同。所以必须分清其发展阶段,来研究在扩张期、景气期、收缩期中分别的特征。
②经济增长与通货膨胀(价格上涨)的关系
既要保持经济快速增长,又要维持较低的通货膨胀
③社会总供给与社会总需求的关系
④工业与农业的增长关系
⑤投资与消费之间的关系
我们以GDP与国民经济主要指标间的关系为例:
基本思路:以历史的GDP增速及相关的指标包括:固定资产投资额(TZ)、工业增加值(GY)、金融机构贷款(DK)、趋势序列值(T)等的数据为基础,建立相应的模型,对它们之间的关系进行模拟,然后对未来3个月的比例关系进行诊断,以此评价统计汇总数据的质量。
数据基础:1978-1998间20年的统计数据。
数据质量控制方法:因子分析法并结合聚类分析
模型类型:多元回归模型+自回归因素
软件支持: SPSS
模型算式:
GDP(t)=+0.28T+1.1GY(t)-2.28TZ(t)+0.28DK(t)
GDP(t)=31.17+4.4GY(t)+[AR(1)=0.26,MA(1)=-0.71]
GDP(t)=18.11-5.02TZ(t)+[AR(1)=0.84,MA(1)=0.35]
GDP(t)=26.55+16.02DK(t)+[AR(1)=0.30,MA(1)=0.87]
(6)其他手段
①可利用投入产出调查的数据来推测现有统计数据的质量
②利用抽样调查的理论,推断和校验总体。
③利用统计大检查的资料,对事实上的虚假统计报表进行动态模拟,以达到惩前毖后的作用。
五、系统应用情况及目前存在的问题
数据质量控制系统的应用始于1998年8月,经过一年多的运转,它对检测统计数据的质量起到了积极和有效的辅助作用。该系统针对北京市国民经济各月的运行情况进行了跟踪监控,协助业务部门尽快发现问题,并将存在趋势性问题的指标作出必要的解释。另一方面,在一年多的运行当中,各监测指标的数据质量级数一级和二级占到90%以上,说明我市经济的增长,是比较客观地反映了经济走势的增长,不存在与趋势上相冲突的大增或大跌。下面附录部分是我局根据数据质量监控系统的方法对2000年1季度统计数据进行监控的结果。
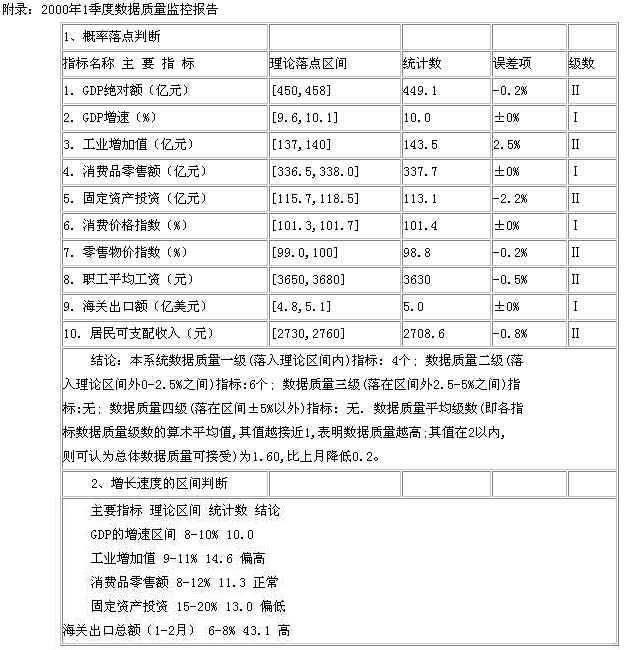
3、各分量指标对总量指标的支撑度判断
运用多元分析方法,选取与GDP密切相关的指标:固定资产投资、工业增加值、银行贷款、消费价格指数、商业零售额的增长速度,与GDP增速进行回归,得到的回归方程为:GDP=1.23+0.14GY+0.12TZ+0.18DK+ 0.08WJ+[AR(1)=0.17,MA(1)=2.15], 然后分别把投资增长13.0%、工业增长14.6%、贷款增长48.6%、消费价格指数101.4%以及商业增长11.3%带入多元回归方程,观察各主要行业的速度能支撑多大的GDP的增长。由此得GDP增速为9.85%,与核算值有0.15个百分点的差距。
4、各专业之间数据的匹配关系的校验
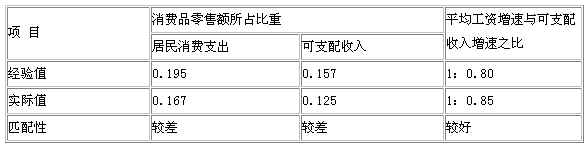
(1)零售额、物价与城镇居民收支之间的关系:
根据对历史资料的研究分析,当消费价格指数在[100,102]区间之内时,消费品零售额(亿元)占居民消费支出(元)的比重约为0.195,消费品零售额(亿元)占居民可支配收入(元)的比重约为0.157。根据1-3月的统计数据,两个系数分别为0.167和0.125,均低于经验数据,两组数据匹配性较差。
2.劳动工资与收入之间的关系:
根据我们测算,平均工资的增长速度与居民可支配收入增速比大致为1:0.8,1-2月职工平均工资增长17.7%,居民可支配收入增长15.0%,两增速之比为1:0.85,两个速度匹配较好。
在运行该系统中,我们还要特别注意几个问题。首先,模型是建立在时间序列的基础之上,尽管已经对历史资料进行了季节调整、修匀以及不规则因素的剔除,但一些政策因素的扰动,很难能通过模型来模拟,因此所建模型不可能达到尽善尽美。其次,“理论区间”或“合理区间”不一定在实际当中合理,落入区间之外,就立即认为它在数据质量上有问题,这种做法是不可取的,在经过认真细致的调查研究之前,不能武断地将其视为异类。另外,该系统属于系统工程,需要多方协调、通盘考虑,切忌一家之言,闭门造“数”。
总之,统计数据的质量监控系统是一个复杂的人工系统。由于统计数据质量的特性使得系统的建立和运转将面临很多的困难和问题。但统计数据的质量是统计工作的生命,笔者认为应该在加大统计执法力度的前提下,尽快引入技术手段,更多地使用数理统计学的方法来解决数据质量问题,更快地构建各专业、各行业相应的控制系统。准确地确立控制点。另外,笔者在本文所确立的控制点不是一成不变的,它是一个循环迭代过程,随着时间和数据的更新,也要做相应变化。
说明:
1.本文只对未来统计数字的可行性进行研究,对于历史数据如有虚假现象,不属于本文所研究的范畴。
2.上述结论是根据数理统计学的有关方法推导出的,纯属学术探讨,不代表官方的观点。
3.文中不尽和纰漏之处,敬请专家批评指正。
参考文献:
1.《时间序列分析—预测与控制》([美]George E.P.Box 中 国统计出版社1997年9月译著)
2. 《统计决策理论与贝叶斯分析》([美]Gregory C.Reinsel 中国 统计出版社1997年9月译著)
3. 《实用数据分析方法》(吴国富等著,中国统计出版社1992年5月出版)
4. 《经济周期与预测系统》(毕大川、刘树成主编,科学出版社1990年6月出版)
来源:《北京市统计局》
扫一扫
在手机打开当前页
 关闭
关闭 湘公网安备 43010202000995号
湘公网安备 43010202000995号

